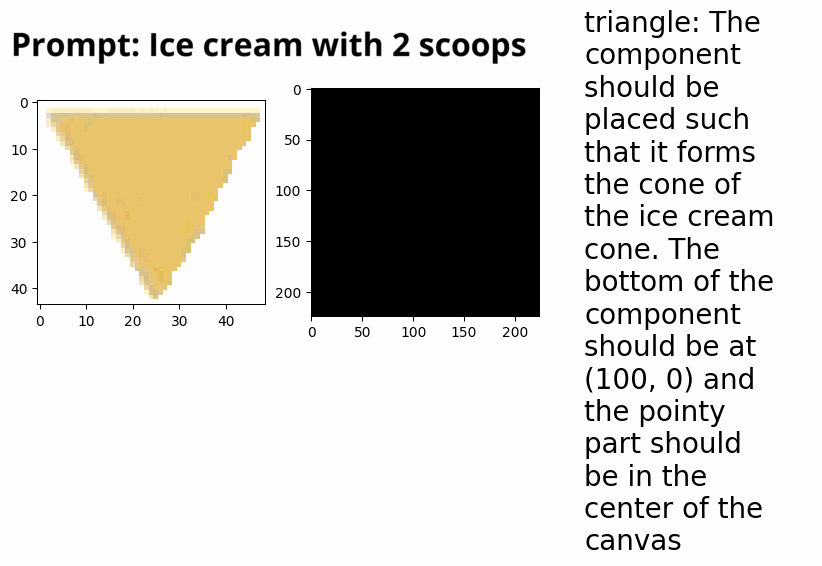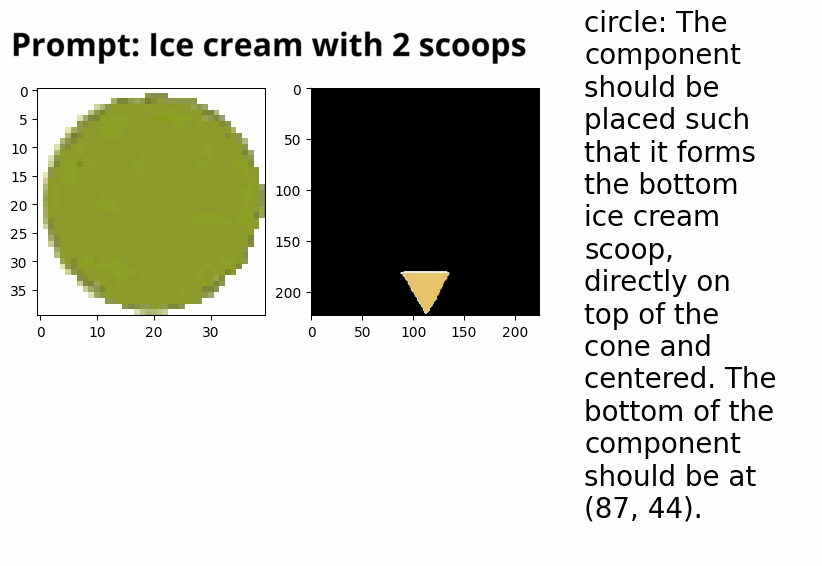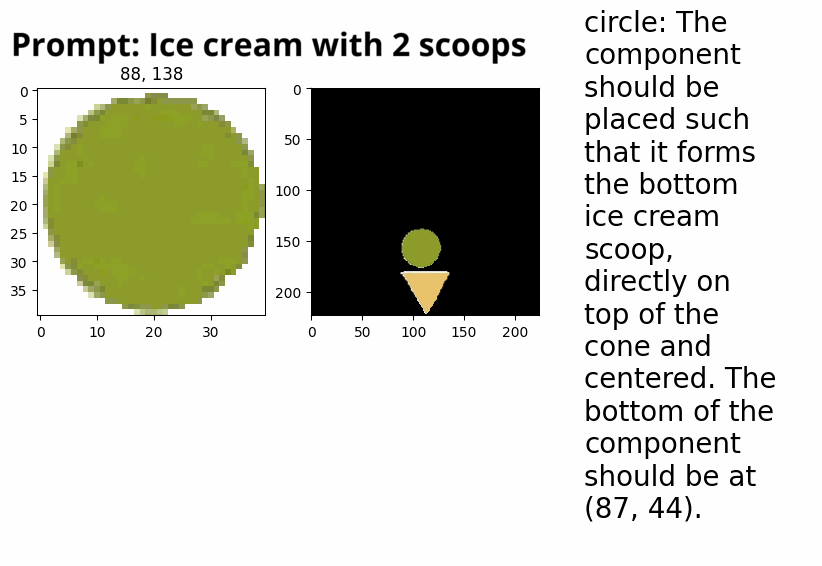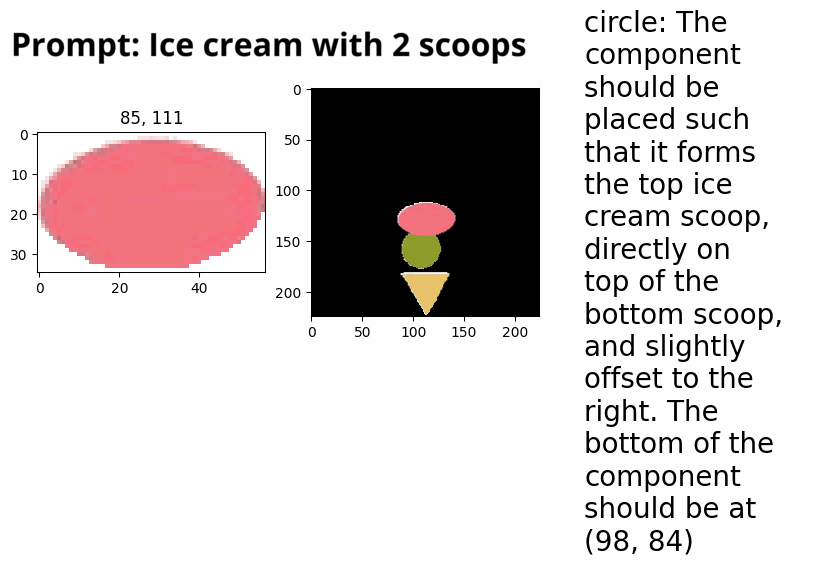
Automatic collage creation with Vision-LLMs (independent research). Winter 2024 → Present
Can LLMs succesfully make collages? This work is an extension of the ‘drawing with VLLM’ work, where, instead of writing SVG code, we allow an LLM to extract segments via text-prompting from collections of existing images, in order to create new images. This explores: LLMs capabilities to identify which image it wants to use, which segment it wants to pick, and whether it can use that segment to create something new with it.